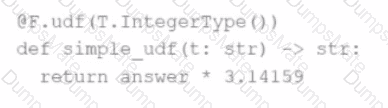
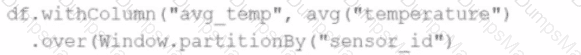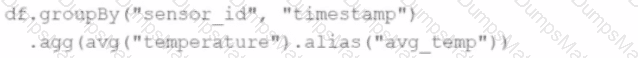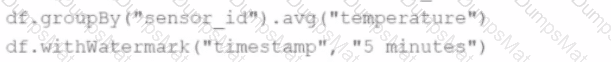Comprehensive and Detailed Explanation From Exact Extract:
Option B is the correct and idiomatic approach in PySpark to split a string column (like email) based on a delimiter such as "@".
The split(col("email"), "@") function returns an array with two elements: username and domain.
getItem(0) retrieves the first part (username).
getItem(1) retrieves the second part (domain).
withColumn() is used to create new columns from the extracted values.
Example from official Databricks Spark documentation on splitting columns:
from pyspark.sql.functions import split, col
df.withColumn("username", split(col("email"), "@").getItem(0)) \
withColumn("domain", split(col("email"), "@").getItem(1))
⚠️Why other options are incorrect:
A uses fixed substring indices (substr(0, 5)), which won’t correctly extract usernames and domains of varying lengths.
C uses substring_index, which is available but less idiomatic for splitting emails and is slightly less readable.
D removes "@" from the email entirely, losing the separation between username and domain, and ends up duplicating values in both fields.
Therefore, Option B is the most accurate and reliable solution according to Apache Spark 3.5 best practices.