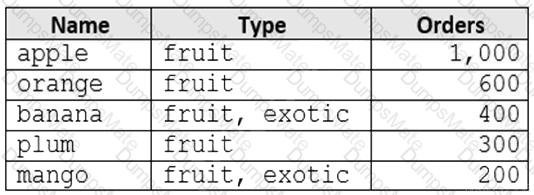
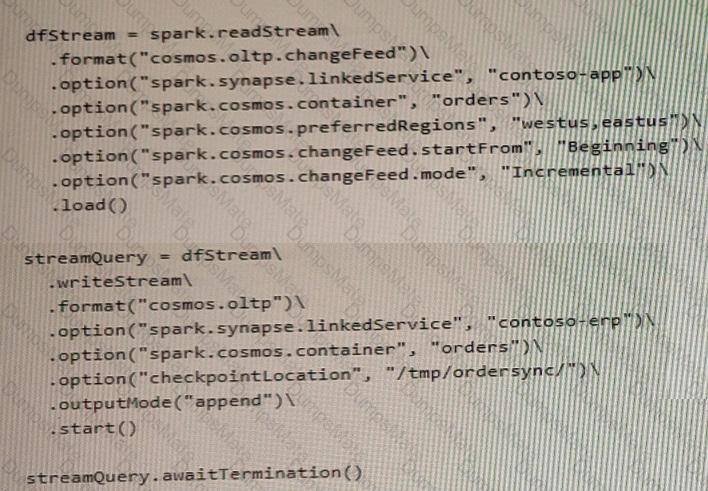
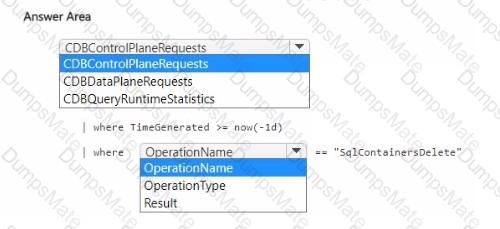
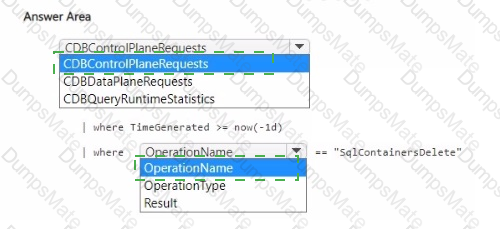
You have a container named container1 in an Azure Cosmos DB Core (SQL) API account.
The following is a sample of a document in container1.
{
" studentId " : " 631282 " ,
" firstName " : " James " ,
" lastName " : " Smith " ,
" enrollmentYear " : 1990,
" isActivelyEnrolled " : true,
" address " : {
" street " : " " ,
" city " : " " ,
" stateProvince " : " " ,
" postal " : " " ,
}
}
The container1 container has the following indexing policy.
{
" indexingMode " : " consistent " ,
" includePaths " : [
{
" path " : " /* "
},
{
" path " : " /address/city/? "
}
],
" excludePaths " : [
{
" path " : " /address/* "
},
{
" path " : " /firstName/? "
}
]
}
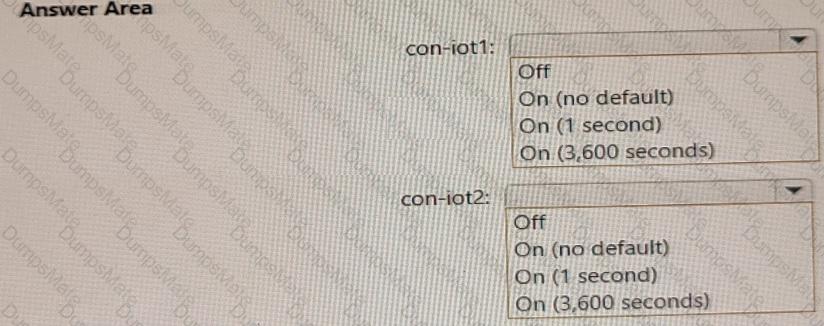
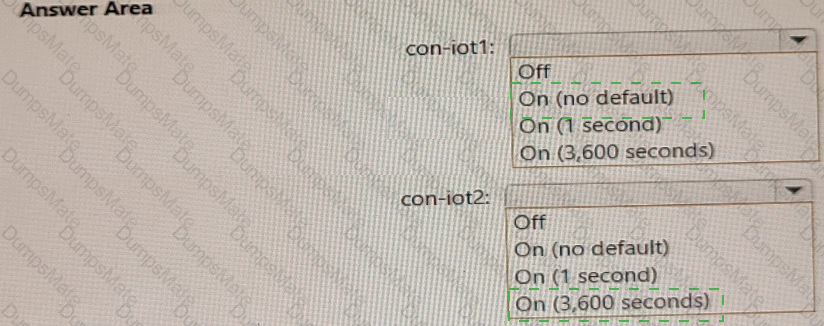
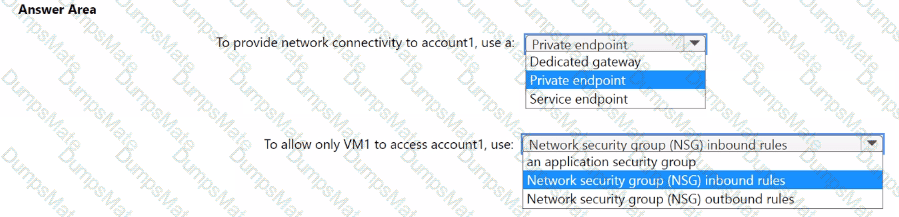
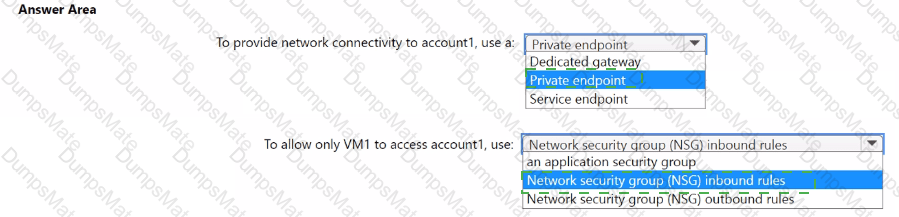
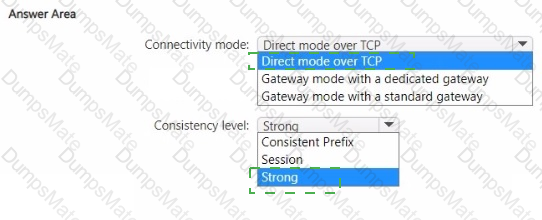
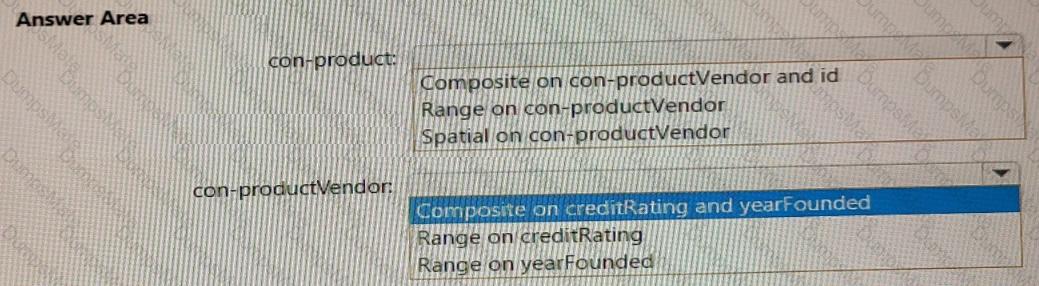
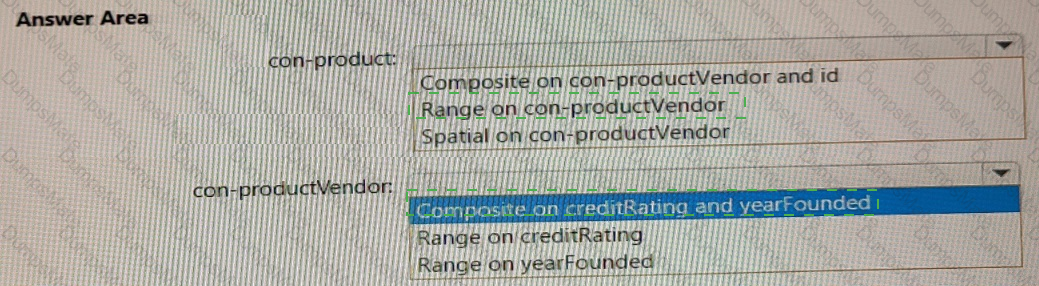
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.